17050在分析数据流中找到子立方体重要元素0Branislav Kveton �0Adobe [email protected]. MuthukrishnanRutgers [email protected] T. Vu †0University of Massachusettshvu@...
”5个标签 数据流分析 子立方体重要元素 一次遍历抽样算法 基于模型的方法“ 的搜索结果

针对上述问题,提出了一种基于概要技术的流数据OLAM 框架——sketch cube(概要立方体),该框架把任意维度组合映射成唯一自然数,根据上下限单调原则对维度组合裁剪,在类线性空间中保存有效数据单元信息,并构建...

如何提高机器学习模型性能, 可从五个关键方面入手。 1. 数据预处理 2. 特征工程 3. 机器学习算法 4. 模型集成与融合 5. 数据增强 以下是各个方面的具体分析和方法: [ 说明:1、这里主要是各个关键方法的...
<SPAN class=Apple-style-span xss=removed><SPAN class=Apple-style-span style="FONT-WEIGHT: 300; FONT-SIZE: 14px; COLOR: rgb(87,87,87)
近几年来,在计算机视觉领域,利用深度学习卷积神经网络技术来实现各种任务的算法越来越多。毫米波雷达、相机、激光雷达、超声波雷达等车载传感器生产成本的降低,汽车的自动驾驶技术得到了飞速发展,在我们的日常...
大数据 IDC将大数据技术定义为:“为更...大数据分析主要涉及两个不同的领域:一是如何将海量的数据存储起来,二是如何在短时间内处理大量不同类型的数据,即解决大数据存储与大数据处理等问题 大数据概览 ...
视觉信息学6(2022)14一种基于学习的高效可视化构造方法孙永健a,李洁a,陈思明b,根纳季·安德里延科c,d,娜塔莉亚·安德里延科c,d,康章娥a中国天津大学智能与计算学院b中国复旦大学数据科学学院c德国弗劳恩...
近年来,随着人工智能技术以及车载感知器件的快速发展,国内外许多传统汽车企业与互联网巨头强强联手,开始在自动驾驶的战场上布局。如图1-1所示,百度、特斯拉、谷歌以及华为等科技公司已经在自动驾驶领域取得了阶段...
数挖掘广义观点:一类深层次的数据分析方法 目的自动抽取隐含的、以前未知的、具有潜在应用价值的模式或规则等有用知识 方法:使用人工智能、机器学习、统计学和数据库等交叉学科领域方法 对象:大规模、不...
在大型数据存储库中,自动地发现有用信息的过程。二、数据挖掘要。
刚去公司的时候,做数据的迁移,写sqoop脚本,(注意:这里可能会问到sqoop增量导入数据的方式式,一般会用到append追加的模式)把数据从oracle数据库导入到hive当中(注意: a.这里我们使用是shell脚本的方式...
经过一周的综述撰写,深感点云算法应用之浩瀚,只能仰仗前辈们的文章作一些整理: 点云硬件: 点云获取技术可分为接触式扫描仪、激光雷达、结构光、三角测距(Triangulation)、以及立体视觉等多种。最近二十...
一、 决策树优点 1、决策树易于理解和解释,可以可视化分析,容易提取出规则。 2、可以同时处理标称型和数值型数据。 3、测试数据集时,运行速度比较快。 4、决策树可以很好的扩展到大型数据库中,同时它的大小...

二元属性:是一种标称属性,只有两个类别状态:0或者1,0通常表示该属性不出现,而1表示出现。二元属性也有对称的二元属性和非对称的二元属性,如果状态的结果不是同等重要的,则称为非对称的二元属性。 对称的二元...
数据仓库要点 第二章 数据仓库 1、B树索引 考题:为何B树等在数据库中广泛使用的索引技术无法直接被引入数据仓库? 1、B树要求属性必须具有许多不同的值,比如身份证号这种取值字段,取值范围很广,几乎没有重复。 2...

一、聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结构...
在整个机器人系统中,机械臂类似于人类的手臂,模仿人手的功能,场对智能机器人的要求愈发严苛,机械臂抓取正在向可靠、快速和精确方向发展,升了粗配准阶段的精度,降低了精配准的计算时间,整体上减少了算法的计算...
一、聚类的概念聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结构...
一、聚类的概念聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结构...
KD-Tree是以二叉搜索树(Binary Search Tree)为原型改进的一种数据结构,当K 为1时,就是标准的二叉搜索树,其树形结构如图3.5所示。它将存储K维空间中所有 的实例点,其树形结构搜索检测空间的实例点具有较好的...
回归模型: 误差项要满足正态分布,无偏性,共方差性,和独立性。用最小二乘法,来评估参数。也有很多非线性模型。 贝叶斯算法: 贝叶斯数据需要离散,不完整数据,没有输入和输出的概念,节点运算独立。 ...
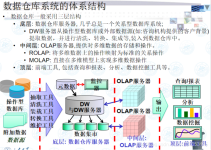
研究方向前沿读书报告数据挖掘技术的算法与应用 目录第一章 数据仓库... 51.1 概论... 51.2 数据仓库体系结构... 61.3 数据仓库规划、设计与开发... 71.3.1 确定范围... 71.3.2 环境评估... 71.3.3 分析... 71.3.4 ...
一节课轻松通关 Spark
标签: spark

我们提出了一种新的方法,包括两个主要部分:生成问题图表示和回答过程,由问题图的抽象结构引导以调用可扩展的可视估计器集合。训练是针对语言部分和视觉部分本身执行的,但与现有方案不同,该方法不需要使用具有...
推荐文章
- 力扣——206.反转链表_力扣链表反转-程序员宅基地
- 如何解决深度冲突(Z-fighting),画面闪烁的问题-程序员宅基地
- Android 第三方库--2017年Android开源项目及库汇总_panel.travel-tv.top-程序员宅基地
- adb链接模拟器_adbconnect连接模拟器-程序员宅基地
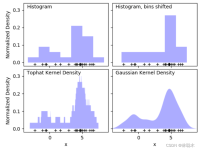
- Python绘图Matplotlib手册-程序员宅基地
- lego-loam阅读理解笔记 一_horizon_angle = atan2(p.x, p.y) * 180.0 / m_pi;-程序员宅基地
- 购物车功能测试用例测试点整理思维导图方式_购物车测试点思维导图-程序员宅基地
- 使用matplotlib绘图实现动态刷新(动画)效果_matplotlib 动态刷新-程序员宅基地
- Apache Kafka 可视化工具调研_kafka-console-ui-程序员宅基地
- 如何编译部署独立专用服务端(Standalone Dedicated Server)【UE4】_ue4 独立服务器搭建-程序员宅基地